Continuous Monitoring of Software Libraries
So you continuously build and deploy your software. You might even have some security scanning integrated in your CI/CD pipelines that checks the libraries you use for vulnerabilities. But what’s the use of that scanning when your application is not being deployed frequently? And your container images? What about vulnerabilities in libraries that are used by vendor-delivered software that you use?
The Usual Setup
More and more organizations have adopted a DevOps way of working where software is deployed to production in a fully automated fashion, which is a concept we call Continuous Deployment. These production deployments often happen multiple times per week or even per day. This is a good thing from a security perspective because it means that the organization is able to quickly update and redeploy its software in case of security vulnerabilities. So far so good.
But how is a DevOps team informed about the presence of security vulnerabilities in their software? That problem isn’t new. There are many tools available to detect vulnerabilities in all aspects of software automatically: scanners that analyze your application code and infrastructure-as-code, tools that scan third-party dependencies for known vulnerabilities, and to some extent, you can even simulate actual attacks on your application. Setting up and integrating such tools in continuous deployment pipelines is an important aspect of the work we do at Booleans Security, and is part of a methodology called “DevSecOps”, or in other words: integrating security into DevOps.
Often, organizations are aware that they should implement some level of security scanning in their deployment pipelines, and it’s common to see them already having SAST (Static Application Security Testing) and SCA (Software Composition Analysis) tools integrated in their pipelines, so that such scans take place for every build. Sometimes, they even run container scanning tools such as Trivy to make sure their container images don’t contain vulnerabilities. A heavily simplified view of their build and deployment pipeline may look like this:

When Things Go Wrong
Let’s take a look at a few nasty scenarios, to illustrate the problem we want to address.
Scenario 1
Our DevOps team creates a new application, and when it’s good enough, it’s deployed to production. In the months following, a few bugs are found, we fix them, we add some new features, and perhaps after a year, less and less changes are implemented in the application, so naturally, the deployment frequency decreases.
Meanwhile, a highly critical vulnerability in a widely used open-source library is discovered by some security researchers, and the details of this vulnerability are disclosed to the public right after a patch is released. A few hours after the public disclosure, the vulnerability gets exploited all around the world, because this is prime time: many applications might not have upgraded the dependency in their application yet, so they may still be exploitable.
Our application uses this library. Fortunately, we’ve thought about scenarios like this, and that is why we’ve integrated SCA tooling in our build pipeline that checks all our application dependencies for known vulnerabilities. However, since our application is not built as frequently anymore, it may take a while before this particular vulnerability pops up. Maybe a week. Maybe a month. Maybe half a year. In the meantime, we’re vulnerable. Not great.
Scenario 2
We prefer not to write our CRM software ourselves because CRM software is not our core business, so we buy it from Big CRM Corp instead, and install it on our own infrastructure. We get an upgrade every 6 months, which we then carefully roll out.
Now the same thing as in scenario 1 happens: a critical vulnerability is published in a widely used open-source library, and the world starts hacking. We have a good eye on our internally developed software, but we’re not so sure about what libraries are being used by our software delivered by Big CRM Corp.
At first, we might not be aware of this critical vulnerability, because, unlike some other organizations, we don’t have a team monitoring threat intelligence information like hawks. Once we become aware of the vulnerability, however, we still don’t know whether the proprietary software we use contains that library, or which version of the library is being used, if at all.
So we ask Big CRM Corp about this once we’re aware of the issue. The vendor may reply that they need to look into it, but assures us that their product is probably not vulnerable. The last thing they want is for their customers to panic. Of course, we don’t buy into the “probably” thing. We want more certainty, so we urge them to make sure of this. Then, after a few days, they reply that they are using the library, but that it’s not clear yet whether they’re vulnerable, and analysis is ongoing. Another few days pass by, and eventually, we’re notified that there is a patch release available that fixes the vulnerability (oh no!), which will then need to be rolled out on our infrastructure. Not great.
The Common Problem
The common problem in both scenarios is that a vulnerability was being disclosed in a third-party library. It wasn’t a vulnerability in our own code, and it wasn’t a vulnerability in our vendor’s code either. Yet because the component was included in our application, we were suddenly under attack because a vulnerability was published while our application was happily running and doing its thing. It didn’t take a code change, there was no new build, there was no new deployment from the external vendor, and all it took was a piece of information being published in the outside world.
Situations like this happen over and over. Log4Shell was somewhat of a crisis. Before that, another big one was CVE-2017-5638 in Apache Struts. Not long after Log4Shell, there was Spring4Shell. At the time of writing, there’s moderate panic about two vulnerabilities in the widely used OpenSSL that are classified as “high”. There are many more, and there will be many more in the future.
Addressing the Problem
So how are we going to make sure that we’re able to respond faster the next time this happens? Fortunately, more and more tooling is emerging to address problems like this. These new tools focus on a concept called SBOM, which stands for Software Bill of Materials. There is some hype around this topic, but an SBOM is just a structured document of all the components an application relies on, including their versions, and possibly some metadata. Beyond an application’s dependencies, this can include packages that reside in a container image or simply OS packages of the underlying infrastructure. There are some standards for SBOMs (since of course, having one standard is never enough), and the most promising ones at the moment seem to be OWASP’s CycloneDX and SPDX.
You may wonder why and how SBOMs can help solve the problems in earlier scenarios, and the truth is that by themselves, they do not. An SBOM is just a document. It won’t do anything by itself. This is where we get to the topic of continuous SBOM monitoring.
SBOM monitoring tools, like OWASP’s DependencyTrack, consume SBOM documents. They get all the components and their versions from the SBOM document, and from then on, all these specific component versions will be monitored for vulnerabilities. Whenever a vulnerability becomes known in its vulnerability databases, the monitoring tool will alert the relevant team within your organization, so the vulnerable component can be upgraded.
For software that you build in-house, this means that right after you deploy to production, you generate an SBOM document from your software (there are several tools for that), and send it to the SBOM monitoring tool from your pipeline. From then on, all component versions that are being used in production will be monitored for vulnerabilities continuously, and alert the DevOps team whenever a vulnerability is found.
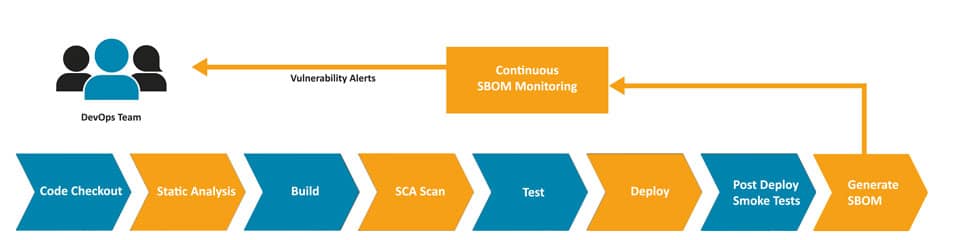
For software provided by vendors, tools like this can also help. It is becoming increasingly common to enforce that vendors deliver an SBOM for every release of their software so that you can upload it to your own SBOM monitoring tool. This will help organizations to have a very clear picture of where risks are in case of an emergency, even when they arise in software delivered by a vendor. To give you an idea of how serious measures like these are regarded worldwide, take a look at the Executive Order published by the U.S. White House recently, where this method of using SBOMs is mentioned explicitly.
Are You Prepared?
Crisis situations like the ones mentioned in this article will happen over and over, and organizations carry a responsibility to have done everything in their power to protect their customers and assets. Responding to published vulnerabilities as fast as possible is an important part of this, according to us. Does your organization have visibility into vulnerable components at all times? How about applications that are in maintenance mode? Do you have an idea of what is being used inside vendor-delivered applications that you’re using? How fast can you act when the next severe vulnerability sees the light of day? If you are not sure, or if you’re sure you’re not, get in touch with us.
![]()
Leendert
Principal Security Specialist
Leendert is an application security specialist focusing on DevSecOps practices, with a background in both software development and technical operations. He sees security as yet another quality aspect of software, always to be taken into account.